LeNet模型介绍
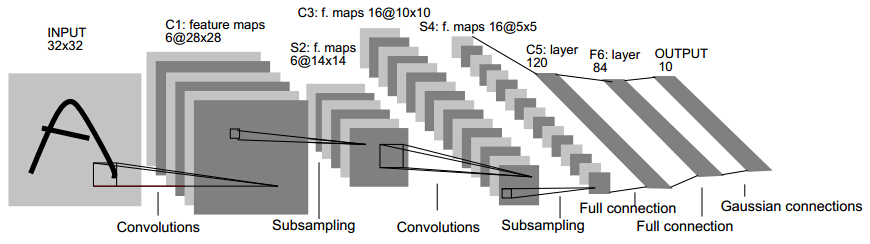
LeNet网络基本架构为:conv1 (6) -> pool1 -> conv2 (16) -> pool2 -> fc3 (120) -> fc4 (84) -> fc5 (10) -> softmax,括号内数字表示channel数。
该网络包含五层,两个卷积(卷积层、池化层),两个全连接层,一个输出层。
其中卷积层的卷积核大小为5x5,stride=1;池化层为最大池化层,卷积核大小为2x2,strides=2;全连接层的输出个数分别为120, 84, 10.
LeNet模型复现
参考:《动手学深度学习》Chapter5
1 | import d2lzh as d2l |
基于Sequntial类构造模型
经历一次卷积层,其高和宽为(h-k+1)*(w-k+1);经历一次池化层,其宽和高减半;这个过程重复两次
第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。这是因为第二个卷积层比第一个卷积层的输入的高和宽要小,所以增加输出通道使两个卷积层的参数尺寸类似。
全连接层的输入形状将变成二维,其中第一维是小批量中的样本,第二维是每个样本变平后的向量表示,且向量长度为通道、高和宽的乘积。全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
1 | net = nn.Sequential() |
输入一个测试数据看看各层的输出形状
1 | X = nd.random.uniform(shape=(1, 1, 32, 32)) |
conv0 output shape: (1, 6, 28, 28)
pool0 output shape: (1, 6, 14, 14)
conv1 output shape: (1, 16, 10, 10)
pool1 output shape: (1, 16, 5, 5)
dense0 output shape: (1, 120)
dense1 output shape: (1, 84)
dense2 output shape: (1, 10)调用GPU计算
这里在安装的时候,不能直接用”pip install mxnet”,要用”pip install mxnet-cu100”cu100需要根据自己的cuda版本来更改
只有安装gpu版本的mxnet,才可使用gpu
1 | def try_gpu(): |
gpu(0)加载数据集
采用小批次训练,每个批次设置为256个
1 | batch_size = 256 |
评估准确度
1 | def evaluate_accuracy(data_iter, net, ctx): |
训练
1 | def train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs): |
1 | lr, num_epochs = 0.95, 35 |
training on gpu(0)
epoch 1, loss 2.3222, train acc 0.102, test acc 0.100, time 2.2 sec
epoch 2, loss 1.5564, train acc 0.396, test acc 0.650, time 2.2 sec
epoch 3, loss 0.8515, train acc 0.667, test acc 0.716, time 2.2 sec
epoch 4, loss 0.6984, train acc 0.722, test acc 0.749, time 2.2 sec
epoch 5, loss 0.6321, train acc 0.750, test acc 0.769, time 2.1 sec
epoch 6, loss 0.5789, train acc 0.771, test acc 0.793, time 2.2 sec
epoch 7, loss 0.5328, train acc 0.790, test acc 0.801, time 2.2 sec
epoch 8, loss 0.4997, train acc 0.805, test acc 0.820, time 2.2 sec
epoch 9, loss 0.4771, train acc 0.815, test acc 0.831, time 2.2 sec
epoch 10, loss 0.4515, train acc 0.829, test acc 0.840, time 2.2 sec
epoch 11, loss 0.4339, train acc 0.837, test acc 0.841, time 2.1 sec
epoch 12, loss 0.4220, train acc 0.841, test acc 0.852, time 2.2 sec
epoch 13, loss 0.4057, train acc 0.849, test acc 0.859, time 2.2 sec
epoch 14, loss 0.3916, train acc 0.854, test acc 0.856, time 2.2 sec
epoch 15, loss 0.3778, train acc 0.860, test acc 0.868, time 2.2 sec
epoch 16, loss 0.3675, train acc 0.865, test acc 0.873, time 2.3 sec
epoch 17, loss 0.3558, train acc 0.868, test acc 0.870, time 2.2 sec
epoch 18, loss 0.3472, train acc 0.873, test acc 0.868, time 2.2 sec
epoch 19, loss 0.3395, train acc 0.875, test acc 0.879, time 2.2 sec
epoch 20, loss 0.3335, train acc 0.878, test acc 0.873, time 2.2 sec
epoch 21, loss 0.3252, train acc 0.881, test acc 0.873, time 2.2 sec
epoch 22, loss 0.3194, train acc 0.882, test acc 0.883, time 2.2 sec
epoch 23, loss 0.3151, train acc 0.884, test acc 0.879, time 2.2 sec
epoch 24, loss 0.3124, train acc 0.884, test acc 0.882, time 2.2 sec
epoch 25, loss 0.3072, train acc 0.886, test acc 0.883, time 2.2 sec
epoch 26, loss 0.3032, train acc 0.888, test acc 0.885, time 2.2 sec
epoch 27, loss 0.2977, train acc 0.890, test acc 0.885, time 2.3 sec
epoch 28, loss 0.2956, train acc 0.891, test acc 0.880, time 2.2 sec
epoch 29, loss 0.2903, train acc 0.893, test acc 0.887, time 2.2 sec
epoch 30, loss 0.2902, train acc 0.893, test acc 0.890, time 2.1 sec
epoch 31, loss 0.2842, train acc 0.895, test acc 0.889, time 2.2 sec
epoch 32, loss 0.2807, train acc 0.897, test acc 0.890, time 2.2 sec
epoch 33, loss 0.2800, train acc 0.896, test acc 0.891, time 2.3 sec
epoch 34, loss 0.2745, train acc 0.899, test acc 0.892, time 2.2 sec
epoch 35, loss 0.2731, train acc 0.899, test acc 0.892, time 2.2 sec



