相关资料:
Chapter2:预备知识
获取和运行本书的代码
环境配置按照官网教程即可实现,可能会遇到一个问题,我的cuda是10.0版本,在修改environment文件时要写成mxnet100,这样就可以运行了。
另外我是在GPU服务器上运行,为了可以在自己的浏览器打开jupyternotebook,需要设置一下,具体设置自行百度,唯一需要注意的是,修改文件后一定要把修改配置前的“#”删去,否则是无效的。
Chapter3:深度学习基础
线性回归
当模型和损失函数形式较为简单时,其误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。
大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)
对于求解数值解,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用,其做法就是选定一个初始点w0,然后w0沿着梯度下降到方向移动一定的距离,知道找到最小点。
线性回归模型实现,比较简单。
softmax回归模型
这本书对softmax回归讲解还是比较详细,尤其是交叉熵这部分,要重点看一下,后面会经常用到。
线性回归的输出是连续的值,但是当我们需要做分类问题的时候,输出往往只有类别之分,是离散的值。softmax回归,其实是在线性回归的基础之上
多层感知机(常用的激活函数)
下面的输出均为-8,8之间随机生成的数值
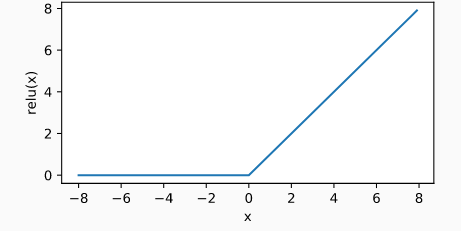
ReLU函数

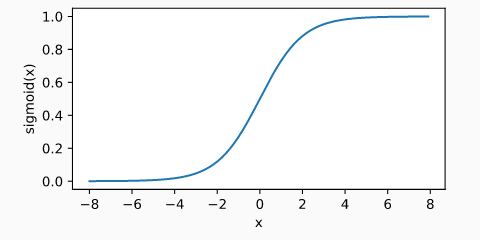
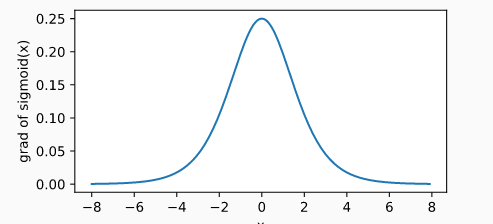
sigmoid函数
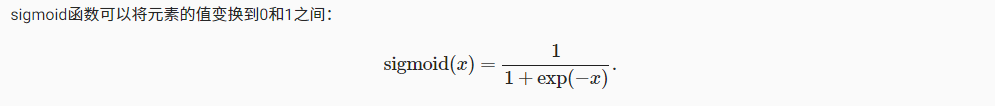
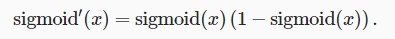
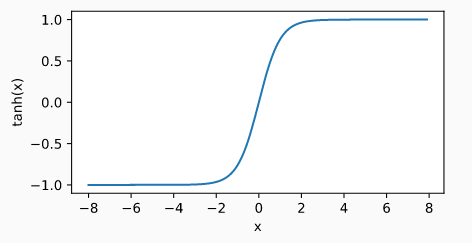
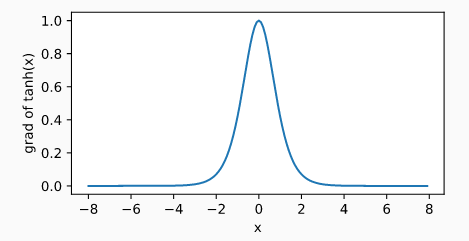
tanh函数
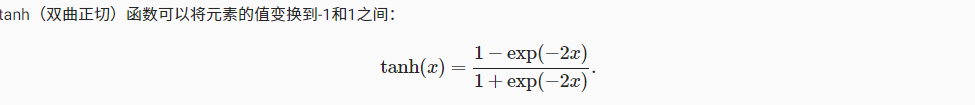
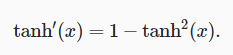
模型选择、欠拟合、过拟合
训练误差:指模型在训练数据集上表现出的误差。
泛化误差:指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。
验证集
预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。例如,我们可以从给定的训练集中随机选取一小部分作为验证集,而将剩余部分作为真正的训练集。
K折交叉验证
在k折交叉验证中,我们把原始训练数据集分割成kk个不重合的子数据集,然后我们做kk次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他k−1k−1个子数据集来训练模型。在这kk次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这kk次训练误差和验证误差分别求平均。
欠拟合、过拟合
一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)
Chapter5
LeNet
https://blog.csdn.net/dan_teng/article/details/87192430





